Media aritmética

Aunque sea de las primeras cosas que aprendemos en un curso de estadística básica, la media es más compleja de lo que parece a primera vista. ¿Qué hacemos cuando hay valores faltantes? ¿O cómo resolvemos el problema de los valores atípicos? ¿Cómo calculamos la media si tenemos una tabla de frecuencias? Sigue leyendo y resuelvo estas dudas.
El objetivo de este tutorial es que puedas asociar el concepto de Tendencia central con el cálculo de la media y que puedas utilizar R para calcularla en distintos escenarios.
Hay dos cosas que voy a hacer en este tutorial que podrían parecer innecesarias:
- Voy a utilizar
dplyr::summariseincluso cuando necesite mostrar una sóla estadística, en lugar de utilizar algo comomean(iris$Sepal.Width).
- Voy a limpiar los nombres del dataset
irisutilizandojanitor::clean_namespara seguir la guía de estilo de código del tidyverse: nombres en minúsculas separando palabras con_en lugar de..
La idea es mostrar un código profesional. Muchos tutoriales utilizan malas prácticas para no agregar una complicación más. Sin embargo, creo que es mejor que te acostumbres a ver un código un poco más complicado pero bien hecho.
library(dplyr)
library(janitor)
iris <- as_tibble(iris) %>% clean_names()Definición de la media
Cuando estamos en el colegio aprendemos que aunque tenemos una calificación distinta para cada asignatura, nuestro rendimiento global se resume con el promedio o la media aritmética. Es una medida de tendencia central, en el sentido de que su valor tiende a estar en el centro de la distribución de frecuencias. En estadística, la representamos con \(\bar{X}\) y se calcula como:
\[ \bar{X} = \frac{\sum_{i=1}^{n}x_i}{n} \]
Donde las \(x_i\) son los valores que queremos promediar y \(n\) es la cantidad de valores que hay. Es decir, podemos leer la fórmula como la suma de los valores dividida entre la cantidad de valores.
¿Cómo se ve la media?
Vamos a graficar la media junto con un histograma. Esto nos ayudará a visualizar dónde está el centro de la distribución.
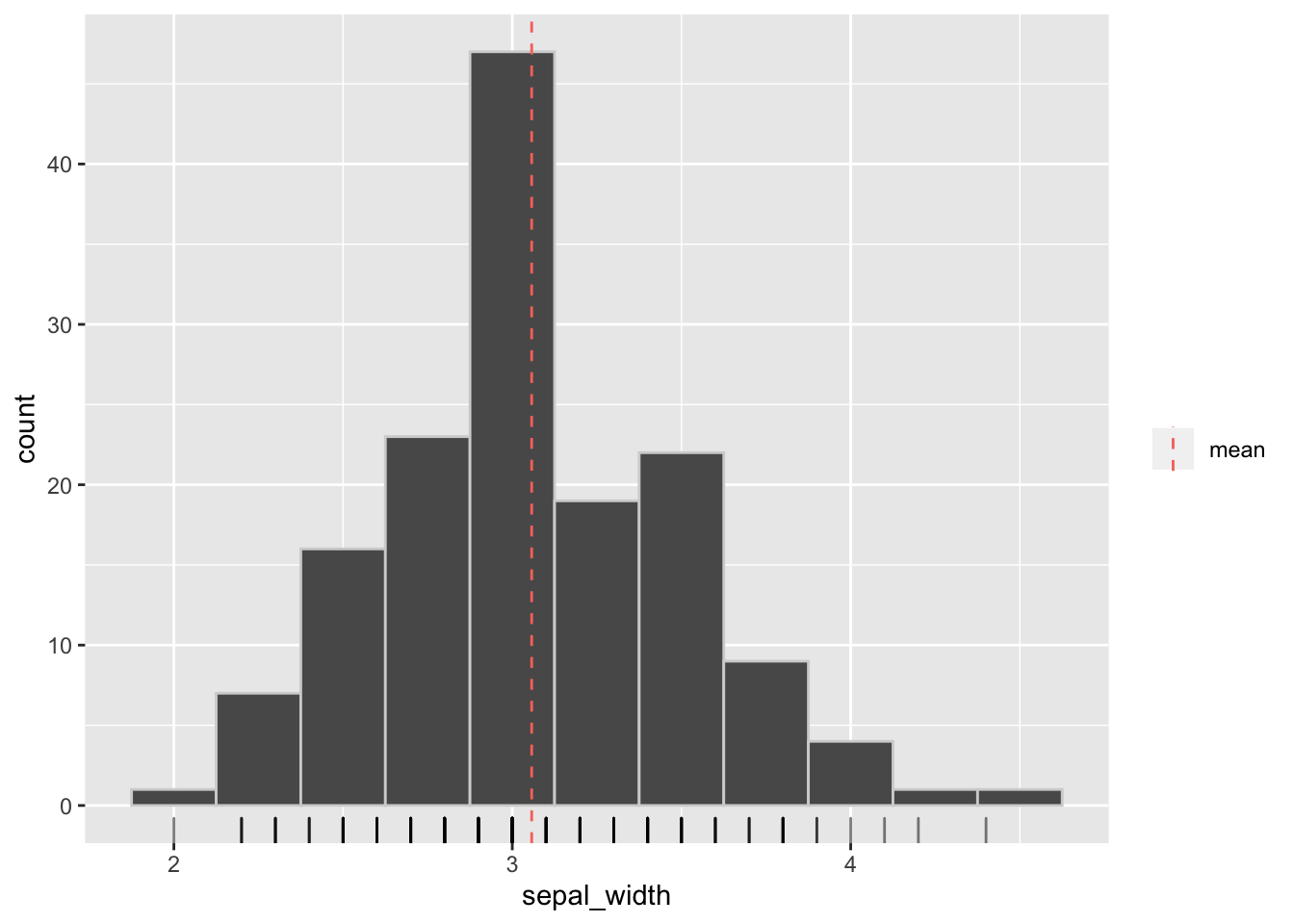
Se puede interpretar la media como el centro de masas de la distribución de frecuencias. Si te imaginas que el eje \(x\) del gráfico es una plataforma, y que las barras del histograma tienen peso, el centro de masa de la plataforma, o el punto donde podrías poner un dedo y que quede equilibrado, estaría aproximadamente donde está la media.
Pregunta
Para calcular la media en R utilizamos la función mean:
iris %>%
summarise(
mean_sepal_width = mean(sepal_width)
)## # A tibble: 1 x 1
## mean_sepal_width
## <dbl>
## 1 3.06Propiedades de la media
Dada una muestra de tamaño \(n\), \(x_1, x_2, ..., x_n\), se puede demostrar que la media aritmética, \(\bar{X}\) cumple con las siguientes propiedades:
- Si a una variable le sumamos una constante o la multiplicamos por una constante, tendremos que sumarle o multiplicarle las mismas constantes a la media. Decimos entonces que la media es un Operador lineal. Formalmente, si aplicamos la transformación lineal \(y_i=ax_i+b\) y calculamos la media, obtendremos el resultado \(\bar{Y}=a\bar{X}+b\).
iris %>%
mutate(
petal_length_plus_one = petal_length + 1,
petal_length_double = petal_length * 2
) %>%
summarise(
petal_length_mean = mean(petal_length),
petal_length_plus_one_mean = mean(petal_length_plus_one),
petal_length_double_mean = mean(petal_length_double),
)## # A tibble: 1 x 3
## petal_length_mean petal_length_plus_one_mean petal_length_double_mean
## <dbl> <dbl> <dbl>
## 1 3.76 4.76 7.52- La media de una constante es la constante. Formalmente, si \(x_1 = x_2 = ... = x_n = c\), entonces \(\bar{X} = c\).
iris %>%
mutate(
constant = 10
) %>%
summarise(
constant_mean = mean(constant),
)## # A tibble: 1 x 1
## constant_mean
## <dbl>
## 1 10- Si substituímos todos los valores de una variable por su media, el total se mantiene igual. Formalmente:
\[ \sum_{i=1}^{n}x_i = \sum_{i=1}^{n}\bar{X} \]
iris %>%
mutate(
sepal_width_mean = mean(sepal_width)
) %>%
summarise(
sepal_width_total = sum(sepal_width),
sepal_width_mean_total = sum(sepal_width_mean)
)## # A tibble: 1 x 2
## sepal_width_total sepal_width_mean_total
## <dbl> <dbl>
## 1 459. 459.Pregunta
- No se puede aplicar la propiedad
- No se puede calcular la media
- Dividir entre una constante es igual a multiplicar por el inverso de la constante
Pregunta
Ignorar los NA al calcular la media
A veces los datos no están completos. En R los datos faltantes se representan con NA. Un dato puede falta por ejemplo cuando:
- La persona no respondió la pregunta porque no sabe o no quiere dar a conocer esta información
- La pregunta ni siquiera aplica a esa persona, como preguntarle edad del hijo mayor a alguien que no tiene hijos
- En datos históricos, para una o varias de las unidades de observación no se tiene acceso a los registros para la fecha
Pueden haber otros motivos, pero con estos es suficiente para que te hagas una idea. Cuando hay datos faltantes, la función mean devuelve NA a menos que le digamos que ignore los NA con na.rm = TRUE. Esta es una caracterísica de casi todas las funciones de agregación como mean, sum y var.
Simular datos faltantes
Para simular una situación real en la que hay datos faltantes, puedes imaginarte que en este paso vamos a lanzar una moneda por cada fila; si cae cara, eliminamos el valor de la columna sepal_width, y si cae sello, lo dejamos. Obviamente no vamos a lanzar una moneda real, sino una moneda virtual simulando varios ensayos de Bernoulli, utilizando la función rbinom(n, size, prob).
No te preocupes si no entiendes mucho este paso; luego lo explicamos mejor en los tutoriales de distribuciones de probabilidad y simulación de variables aleatorias. Lo importante es que nos vamos a quedar con el data.frame llamado iris_na que tiene aproximadamente el 50% de datos faltantes en la columna sepal_width.
set.seed(1234567890)
iris_na <- iris %>%
mutate(
is_na = rbinom(n(), 1, 0.5),
sepal_width = if_else(is_na == 1, NA_real_, sepal_width)
)
iris_na## # A tibble: 150 x 6
## sepal_length sepal_width petal_length petal_width species is_na
## <dbl> <dbl> <dbl> <dbl> <fct> <int>
## 1 5.1 NA 1.4 0.2 setosa 1
## 2 4.9 3 1.4 0.2 setosa 0
## 3 4.7 NA 1.3 0.2 setosa 1
## 4 4.6 NA 1.5 0.2 setosa 1
## 5 5 NA 1.4 0.2 setosa 1
## 6 5.4 NA 1.7 0.4 setosa 1
## 7 4.6 3.4 1.4 0.3 setosa 0
## 8 5 NA 1.5 0.2 setosa 1
## 9 4.4 NA 1.4 0.2 setosa 1
## 10 4.9 NA 1.5 0.1 setosa 1
## # … with 140 more rowsMira ahora la diferencia entre usar na.rm = TRUE y no hacerlo.
iris_na %>%
summarise(
mean_sepal_width_na_rm = mean(sepal_width, na.rm = TRUE),
mean_sepal_width = mean(sepal_width)
)## # A tibble: 1 x 2
## mean_sepal_width_na_rm mean_sepal_width
## <dbl> <dbl>
## 1 3.05 NAMedia truncada
La media es un estadístico no robusto. Esto quiere decir que sensible a los valores atípicos. Intuitivamente, un valor atípico es un valor que no se parece al resto de los valores en un conjunto de datos por ser muy alto o muy bajo. Volviendo al ejemplo de las calificaciones, si tus notas en la mayoría de las asignaturas están entre 11 y 13, pero obtuviste 20 en matemáticas, ese 20 es un valor atípico, y va a halar el promedio hacia arriba, haciendo que tu promedio de una mejor impresión de lo que es tu rendimiento usual. Una manera de solucionar esto es usar una media truncada, en la que eliminamos cierta fracción de los datos más altos y más bajos. En R especificamos esta fracción con el argumento trim.
library(dplyr)
library(janitor)
iris <- as_tibble(iris) %>% clean_names()
iris %>%
summarise(
mean_sepal_width_trim = mean(sepal_width, trim = 0.2),
mean_sepal_width = mean(sepal_width)
)## # A tibble: 1 x 2
## mean_sepal_width_trim mean_sepal_width
## <dbl> <dbl>
## 1 3.04 3.06Media ponderada
En algunos casos, hay observaciones que pesan más que otras. También puedes tener una tabla de frecuencias, especificando cada valor y la frecuencia con la que aparece. En estos casos, debemos tomar en cuenta estos pesos o frecuencias al calcular la media. La fórmula de cálculo es la siguiente:
\[ \bar{X} = \frac{\sum_{j=1}^{m}{f_j * x_j}}{\sum_{j=1}^{m}{f_j}} \]
Donde los \(f_j\) son los pesos o frecuencias de los \(x_i\). Para calcular una media ponderada en R utilizamos la función weighted.mean:
df <- tribble(
~x, ~f,
1, 10,
2, 20,
3, 30,
4, 40
)
df %>%
summarise(
simple_mean_x = mean(x),
weighted_mean_x = weighted.mean(x, f)
)## # A tibble: 1 x 2
## simple_mean_x weighted_mean_x
## <dbl> <dbl>
## 1 2.5 3Fíjate cómo la media ponderada es más alta que la media simple porque los valores 3 y 4 tienen más peso que los valores 1 y 2.
Conclusión
En R es muy fácil hacer cálculos estadísticos. De este tutorial, probablemente lo más iportante es cómo resolver el tema de los valores faltantes o NAs, ya que esto puede darte algunos dolores de cabeza si no sabes que tienes que utilizar la opción na.rm. Además, este truco es útil para otras funciones de agregación.